Expedite data science prototypes to production through model-ready analytic tooling.
MapLarge aids data scientists in productionalized machine learning or 'ML Ops' by providing a data analytics suite of capabilities spanning a 6-step ML Ops process. This engineering process addresses use case requirements from problem definition through production deployment of machine learning models. These steps include:
1. Problem Definition and Framing: articulating the use case with relevant machine learning approaches and analytic methods applicable to the problem.
2. Data Sourcing & Acquisition: identifying and accessing the pertinent data types and data classes in a common analysis platform.
3. Data Handling & Storage: creating ETL workflows supporting ingest, transformation, transport, storage, and monitoring.
4. Data Manipulation & Preparation: employing an ETL workflow to clean, prepare, manipulate, and segment data for testing and validation.
5. Build, Test, Evaluate, Iterate, and Optimize: developing or accessing a model using machine learning tools, services, and frameworks. The wrapping or integrating of a model into an ETL workflow for model maturation.
6. Production Model Deployment: deploying and managing the model’s lifecycle from application stack integration through retirement.
Use Production-Grade Data Analytics for Data Science Prototyping at Scale
MapLarge provides In-house data scientists and software engineers data analytic tools to support the artificial intelligence and machine learning model lifecycle on production scale data. MapLarge’s ETL Notebooks feature allows R&D teams to deploy models on production data without requiring a re-factor to operationalize. In addition to its own internal notebooks MapLarge also supports integration with Jupyter Notebooks, Atom Hydrogen, R, Python, Open Neural Networx Exchange (ONNX), TensorFlow, PyTorch, ML.Net and many others.
DATA INGEST AND TRANSPORT

Intelligent Recurring Scheduling

Push/Pull As Appropriate

Centralized Curated Data Access

Dynamic Configurable Data Synchronization

Full ETL Suite
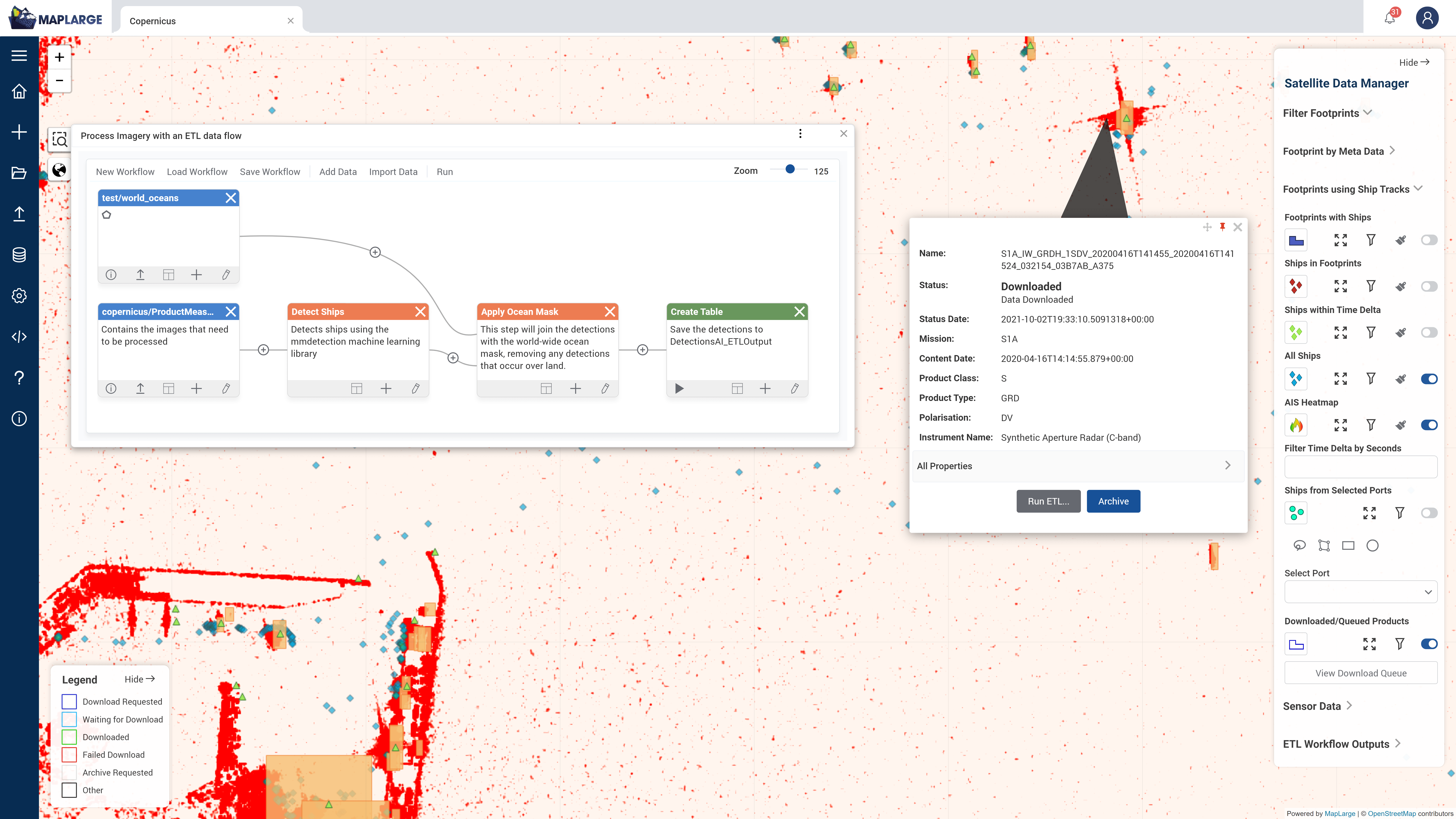
MapLarge ETL Notebooks enables integration of 3rd party machine learning models in a reusable workflow. In this example, an activity model identifies an object of interest to cue download and mapping of Synthetic Aperture Radar (SAR) data. Machine learning scripts execute object detection on SAR imagery to generate ship detections and approximate dimensions for correlation with Automatic Identification System (AIS) ship tracks points and AIS metadata ship identification characteristics.
DATA INGEST AND TRANSPORT
Intelligent Recurring Scheduling
Push/Pull As Appropriate
Centralized Curated Data Access
Dynamic Configurable Data Synchronization
Full ETL Suite
MapLarge aids technical users in rapid prototyping of data science apps through simplified access to publicly available data sets. In this example, MapLarge enables single-click data ordering to access the Sentinel constellation’s petabyte scale SAR data repository. This acquisition process is automatable in the ETL Notebooks feature set.
FRAMEWORK SUPPORT

Vertex AI

ONNX

Glow

Core ML

ML.NET

Azure Machine Learning

SageMaker
Accelerate Data Science Driven Apps via Open Standards and Community Ecosystem Support
MapLarge helps enterprises connect their in-house staff and proprietary data/systems to tools, services, libraries, and environments available to the broader data science ecosystem. By using MapLarge’s ETL Notebooks feature, these external integrations are realized with faster time-to-value in a compliant, auditable, and traceable solution methodology.
FRAMEWORK SUPPORT
Vertex AI
ONNX
Glow
Core ML
ML.NET
Azure Machine Learning
SageMaker
Provide Flexible Coding Options for Data Scientists and Software Engineers
MapLarge’s extensibility provides data scientists freedom in language choice (Python, R, Node, & C#), libraries, and ecosystems support based on preference and comparative advantage. For software engineers, the platform supports common object-oriented and web framework languages: C++, C#, Java, Javascript, Typescript, and Python.
LANGUAGE SUPPORT

C++

C#

Java

JavaScript, TypeScript

Python
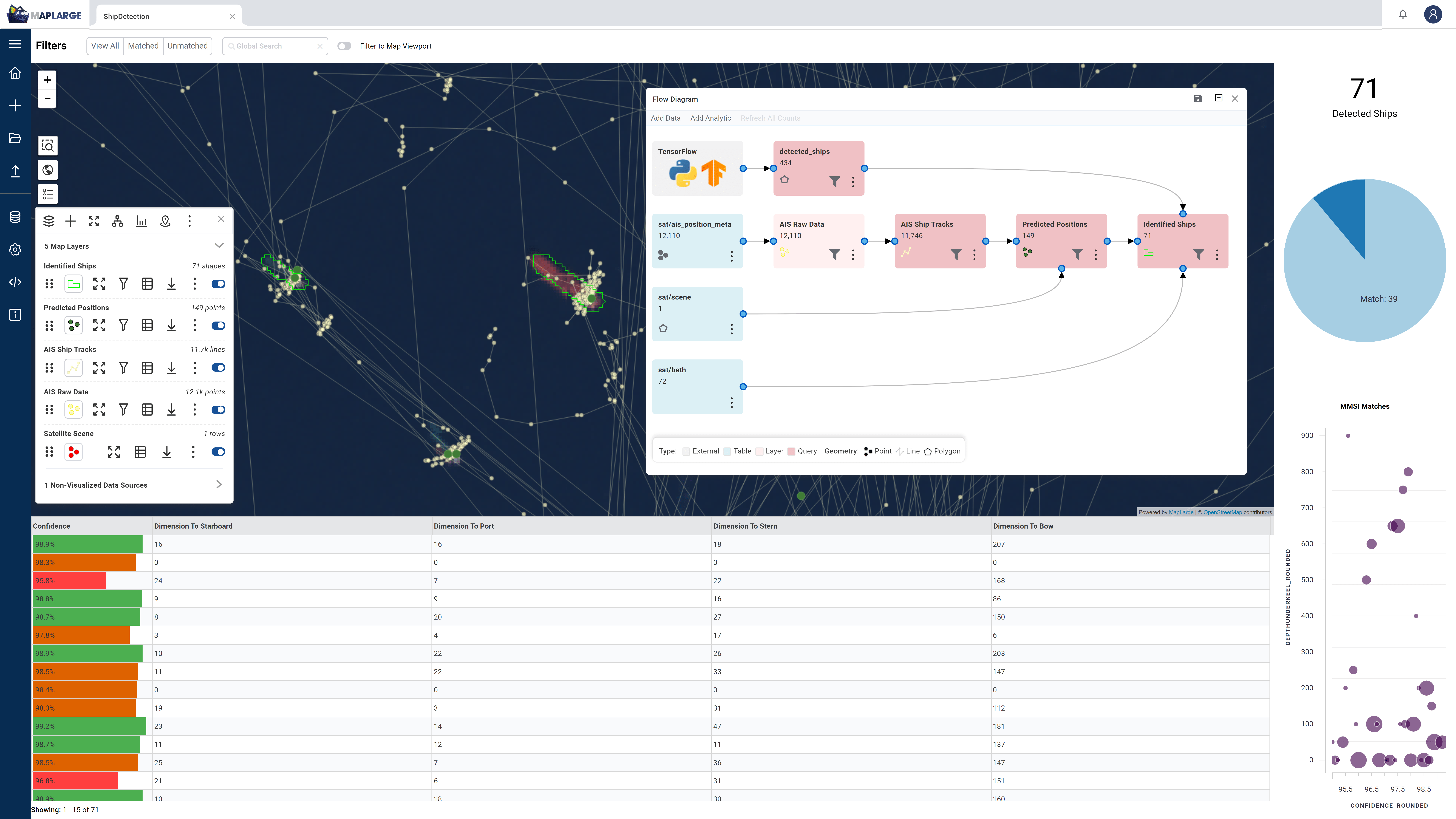
Cross-referencing vessels and wake dimensions with AIS track metadata helps identify possible AIS spoofing and dark ships. Advanced GIS mapping of multiple sensor phenomenologies aided by machine learning helps analysts maintain track custody over large geographic areas.
LANGUAGE SUPPORT
C++
C#
Java
JavaScript, TypeScript
Python











